청) 컨트롤러(뷰) - 글 쓰기 기능 (5편 2/3) - django 강좌
14 Jul 2008지난 글에서 django 에 있는 admin 기능을 이용해 글을 썼고, 글 목록 기능과 글 낱장 보기 기능을 만들어서 작성한 글을 출력했다. 이번 글에서는 django admin 기능을 쓰지 않고 직접 글 쓰기 기능을 만들 것이다. 달랑 하나 만들어? 하는 생각이 들겠지만, 은근히 까다로운 내용이 좀 있으니 서두르지 말고 천천히 익혀 나가자.
아참, 이 강좌는 RSS 구독기에서 볼 경우 화면이 깨지거나 제대로 나오지 않을 수 있다. 우리가 만들 블로그 템플릿에 쓸 HTML 태그가 들어가고 이걸 xmp 라는 HTML 태그들을 출력하는데, 일부 RSS 구독기에서는 xmp 태그를 지원하지 않는다. 되도록이면 웹으로 바로 접근해서 읽기를 권한다.
글쓰기 기능 추가 기반 작업
우선 글쓰기 기능을 쓰는 데 필요한 주소를 추가해야 한다. 주소는 /blog/write 라고 하고, 연결할 함수는 write_form 이라고 할 것이므로, urls.py 에는
(r'^blog/write/$', 'hannal.blog.views.write_form'),
이런 주소 체계를 추가하고, views.py (blog 디렉토리에 있는 views.py)에는
def write_form(request): pass
이렇게 만들면 된다. 글쓰기 화면은 컨트롤러(뷰)에서 딱히 할 게 없다. 글쓰기 화면용 템플릿 파일을 읽어와서 출력하면 그만이다(글 고치기 화면 얘기는 나중에 하자). 지난 글에서 이미 템플릿을 가져와 출력하는 건 해봤으니 가져와서 붙여넣어 해치우자.
def write_form(request): page_title = '블로그 글 쓰기 화면' tpl = loader.get_template('write.html') ctx = Context({ 'page_title':page_title }) return HttpResponse(tpl.render(ctx))
write.html 을 가져와 출력하기로 했으니 write.html 을 만들어야 한다.
<h1></h1> <form method="post" action="/blog/add/post/"> <p><label for="title">제목</label><input type="text" id="title" name="title" value="" /></p> <p><label for="category">글 갈래</label><select name="category" id="category"></select></p> <p><label for="tags">글 꼬리표</label><input type="text" id="tags" name="tags" value="" /></p> <p><textarea id="content" name="content"></textarea></p> <p><input type="submit" value="써넣기" /></p> </form>
HTML 에 대한 내용은 이곳에서 다루지 않을 것이니 각 HTML 태그 쓰임새를 모르겠다면 직접 찾아서 익히길 바란다. 다만 한 가지 눈 여겨 봐야할 점은 폼 내용을 전송할 주소가 /blog/add/post/ 라는 점인데, 이 내용을 urls.py 와 views.py 에도 추가하자.
(r'^blog/add/post/$', 'hannal.blog.views.add_post'),
위 내용은 urls.py 에,
def add_post(request): pass
위 내용은 views.py 에 넣는다.
HTTP Request
HTTP 로 서버로부터 뭔가를 요청(Request)하는 방식은 크게 GET 방식과(method) POST 방식이 있다. 각 방식 차이는 스스로 인터넷에 있는 설명글에서 알아보길 바라며, 여기서는 좀 많이 간단히 알아보려 한다. GET 방식은 URI ( Uniform Resource Identifier )를 통해 값을 전달하고, POST 방식은 눈으로는 보내는 값을 바로 확인할 수 없지만 파일도 첨부해서 보낼 수 있다. 좀 더 기술 느낌나게 설명하자면 GET 방식은 HTTP 헤더에 값을 넣고, POST 방식은 HTTP 본문에 값을 넣는다. GET 방식은 HTTP 헤더 제약을 받기 때문에 보낼 수 있는 값 양(길이)에 제한이 있고(웹브라우저 마다 다르다), POST 방식은 제한이 없다고 볼 수 있다(웹서버 마다 다름).
django 는 http 로 넘어오는 각종 값들을 request 에 넣어서 넘겨준다. 그렇다. add_post 니 뭐니 우리가 컨트롤러 안에 만든 함수에 빠지지 않고 들어가 있는 request 가 그 request 이다. GET 방식으로 넘어오는 값은 urls.py 를 이용해 컨트롤러에 있는 함수에 넘겨주는 인자로 받을 수도 있고, request.GET 객체에서 꺼내 쓸 수 있다. POST 방식은 request.POST 객체에서 꺼내 쓸 수 있다. 예를 들면, hannal 이라는 이름으로(key) hello world 라는 값을(value) GET 방식으로 보낸다면 request.GET['hannal'] 에 hello world 가 들어가 있다.
POST 방식으로 넘어오는 값 받아내기
한 번에 글 내용 다 받아다 DB에 넣지 말고 글 내용 받는 걸 차근 차근 보자.
def add_post(request): entry_title = request.POST['title'] return HttpResponse('hello %s' % entry_title)
return HttpResponse 부분은 익숙한 부분이니 설명은 생략한다. entry_title = request.POST['title'] 이 줄에서 앞서 설명한 request.POST['title'] 가 있다. POST 방식으로 넘어오는 값을 받으려고 request.POST 객체를 썼으며 글쓰기 폼(form) 내용 중 글 제목을 title 이라 했으므로 ( <input type="text" id="title" name="title" value="" /> ) ['title'] 라고 해서 request.POST['title'] 가 된 것이다. 이렇게 받은 값을 entry_title 이라는 변수에 넣은 뒤 출력했다.

이제까지 작업한 코드들을 저장하여 django 내장 웹서버를 재구동한 뒤 http://localhost:8000/blog/write 에 가서 글 제목을 써넣은 후 “써넣기” 단추를 누르면 hello 뒤에 여러분이 써넣은 글 제목이 함께 붙어 나온다.
넘어온 값 검사하기
예전에 글 정보 모델(Entries)을 만들 때 반드시 글 제목이나 본문 같은 걸 쓰도록 모델에서 설정했다(null=False 이렇게). 그런데 이렇게 모델에서만 처리하면 DBMS 에 문제가 생긴 것인지 아니면 Unicode 같은 문제인지 아니면 반드시 써넣어야 하는(Null을 허용하지 않는) 요소가 빠져서 문제가 생긴 것인지 얼른 알기 어렵다. 또, 넘겨 받은 값을 모델을 통해 DB에 넣기 전에 그 값이 제대로 된 값인지(숫자만 들어와야 하는데 문자가 들어왔다든가) 확인을 하고 싶은데, 모델로 바로 값을 넘기면 그런 검사를 할 수 없다.
그래서 컨트롤러에서 값을 먼저 검사해야 한다. 마치 지난 글에서 쪽 번호가 숫자인지 아닌지 검사한 것처럼.
글 제목이 HTTP Post 방식으로 넘어왔는지 확인하려면 어떻게 해야 할까? 단순하게 생각하면
if request.POST['title'] == None: pass
이렇게 하면 될 것 같은데, 애초 ['title'] 이게 없다면 위 코드는 오류가 난다.
![]()
request.GET 객체나 request.POST 객체는 파이썬에 있는 딕셔너리(Dictionary) 자료형과 비슷한 자료형이다. 파이썬 딕셔너리 자료형은 has_key 라는 메소드를 제공한다. 이 메소드는 해당 자료에 지정한 키(key)가 있는지 확인해서 참(True)/거짓(False) 값을 반환한다.

django 의 request 객체도 마찬가지이다. 그럼 has_key 메소드를 이용해보자.
if request.POST.has_key('title') == False: return HttpResponse('글 제목을 입력해야 한다우.')
확인해볼 겸 title 을 title2 라고 바꿔서 해보자.
if request.POST.has_key('title2') == False: return HttpResponse('글 제목을 입력해야 한다우.')
그런 뒤 글 작성을 해보면 “글 제목을 입력해야 한다우”라는 문자열이 뜬다.
그런데 딕셔너리 자료형을 쓰면 될 것이지 왜 딕셔너리 자료형과 비슷한 별도 개체(QueryDict)를 만들어 쓰는걸까? 공식 문서에 이에 대한 답이 있다. 이유는 HTML 폼 태그 중 select 태그처럼 똑같은 키에 값이 여러 개가 들어 올 수 있는 경우가 있기 때문이다.
위 코드는 다시 원래대로 바꾸고, 글 제목이 한 글자라도 써있는지 확인하는 코드를 넣자. 위 코드에서 request.POST['title'] 가 존재하지 않는 경우를 처리 했으니, 위 if 조건문에 걸리지 않는다면 request.POST['title'] 이 변수가 존재한다고 할 수 있다. 그러므로 if 조건문 문법인 else 문을 쓰면 된다.
if request.POST.has_key('title') == False: return HttpResponse('글 제목을 입력해야 한다우.') else: if len(request.POST['title']) == 0: return HttpResponse('글 제목엔 적어도 한 글자는 넣자!') else: entry_title = request.POST['title']
위 코드에서 생소한 부분은 len 함수이다. len 함수는 파이썬에서 기본으로 쓸 수 있는 built-in 함수로 length 를 줄인 말이다. 이 함수는 문자열 길이나 tuple, list 자료형의 키 개수(방 개수?)를 반환한다. len('hannal') 이라고 하면 숫자 6이 뜨는데 문자열 길이가 6이기 때문이다. 이 len 함수를 이용해서 request.POST['title'] 길이가 0이면, 즉 한 글자도 없으면 글 제목을 제대로 넣으라는 문자열이 뜬다.
이런 식으로 글 본문도 값을 검사하면 된다.
if request.POST.has_key('content') == False: return HttpResponse('글 본문을 입력해야 한다우.') else: if len(request.POST['content']) == 0: return HttpResponse('글 본문엔 적어도 한 글자는 넣자!') else: entry_content = request.POST['content']
글쓰기 폼 영역에 글 갈래(category) 목록 나타내기
아까 우리는 글쓰기 화면에서 글 갈래 목록을 화면에 뿌리지 않았다. 이미 만들어둔(지난 글에서 django admin 기능을 이용해 글 갈래 모델(Categories)을 통해 DB에 바로 글 갈래를 넣었다) 글 갈래를 글쓰기 화면에 출력하여 글을 쓸 때 그 글이 속할 글 갈래를 지정해야 한다.
DB에 넣어둔 글 갈래를 가져와야 한다는 말은 글 갈래 모델을 통해 글 갈래들을 가져와야 한다는 말이기도 하다. 우선
from hannal.blog.models import Entries
views.py 파일 맨 위쪽에 있는 저 문장을
from hannal.blog.models import Entries, Categories
이렇게 바꿔야 한다. 바꾼다기 보다는 Categories 모델을 가져오라고 추가한 것이다. 이번엔 글쓰기 영역을 출력하는 write_form 함수(def write_form)에서 글 갈래를 가져오도록 해야 한다.
categories = Categories.objects.all()
그런 뒤 write.html 에서 쓸 수 있도록 치환자를 등록한다.
ctx = Context({ 'page_title':page_title, 'categories':categories })
마지막으로 write.html 에서 글 갈래를 출력한다.
{% for category in categories %}
<option value=""></option>{% endfor %}
간단하다. 새로운 내용은 없으며 이미 우리가 이 강좌에서 익힌 내용들이다. 이제는 글 쓰기 화면에 글 갈래도 나열되어 글 쓸 때 하나 고를 수 있다.
글 쓰기 화면에서 글 갈래를 골랐다면 서버로 글 내용을 보냈을 때 글 갈래 정보를 가져와야 한다. 이용자 글쓰기 화면에서 글 갈래를 고르면 그 글 갈래의 일련번호(id)가 서버로 날아가는데, 서버에서는 이 숫자를 그대로 넣으면 안된다. 그 숫자(id)가 실제로 글 갈래 모델(Categories)에 있는 것인지 확인한 뒤에 글 정보 모델(Entries) 관계 상황에 맞게 넣어야 한다. 말은 복잡하지만 한 두 줄로 처리할 수 있으니 겁 먹을 필요는 없다.
먼저 이용자가 입력한 글 갈래 정보가 DB 에 있는지 확인하여 있으면 그 글 정보를 가져오고, 없으면 잘못된 글 갈래 정보라고 안내하는 코드를 만든다. 말은 복잡하지만 구현은 아주 단순하다.
try: entry_category = Categories.objects.get(id=request.POST['category']) except: return HttpResponse('이상한 글 갈래구려')
글 갈래가 숫자이든 아니든 상관없이 Categories 모델을 통해 DB에서 이용자가 입력한 글 갈래 정보로 글 갈래 정보를 가져오게 한다. 있다면 가져올 것이고, 없다면 “이상한 글 갈래구려”라고 안내말이 뜬다. 없는 것 뿐만 아니라 글 갈래 값을 글 갈래 일련번호(id)가 아닌 이상한 문자열로 조작해 보낼 경우에도 저 안내말이 뜬다. 왜냐하면 그런 자료가 없어서 예외 상황 오류(except)가 발생하기 때문이다. 꼼꼼하게 예외 상황을 따지던 강좌 내용에 비해 참 허망할 정도로 단순하다. ^^
자, 정말 글 갈래 정보를 제대로 처리했는지 확인해볼까?
return HttpResponse('hello %s' % entry_category.Title)
이렇게 한 뒤 글을 써보면 화면에는 hello 문자열 뒤에 글쓰기 화면에서 지정한 글 갈래의 이름이 나타난다.
글 꼬리표 넣기
글 꼬리표는 다소 처리가 귀찮다. 그리고 여태껏 다루지 않은 내용도 나온다.
글 꼬리표는 글 하나에 여러 개 붙을 수 있다. 그래서 꼬리표들은 한 자료형에 여러 값을 구분해서 넣을 수 있는 tuple 자료형이나 list 자료형에 넣어서 반복문으로 넣거나 꺼내 것이 편하다. 이용자가 입력한 꼬리표가 한 개이든 100개이든, 혹은 하나도 없든 구분하지 않고 꼬리표는 list 자료형에 담기로 하고, 이용자가 꼬리표를 입력했는지에 따라 이 자료형에 꼬리표를 넣을지 말지 결정하면 된다.
if request.POST.has_key('tags') == True: pass else: tag_list = []
꼬리표가 없는 경우부터 보면, 이용자가 입력한 꼬리표가 없으므로 아무 값이 없는 빈 list 자료형으로 tag_list 변수를 만들었다.
이번엔 꼬리표가 있는 경우이다. 꼬리표는 쉼표로 구분해서 받기로 한다. “django 장고 파이썬”이라고 한 경우 이 긴 문자열이 꼬리표 하나지만 “django, 장고, 파이썬”이라고 하면 django와 장고, 그리고 파이썬이라는 꼬리표 세 개를 쓰는 것이다. 방법은 간단하다. 이용자가 입력한 문자열에 쉼표(,)를 기준으로 문자열을 쪼개면 되는데 이건 파이썬에서 문자열(str, unicode)에 기본 탑재된(built-in) 메소드인 split 을 쓰면 된다.
'django, 장고, 파이썬'.split(',')
이렇게 하면 list 자료형으로 문자열을 쪼개 넣는다. 그런데 위와 같이 하면
['django', ' 장고', ' 파이썬']
이렇게 쉼표 뒤에 있던 공백도 포함되어 들어간다. 우리가 원하는 꼴은
['django', '장고', '파이썬']
이렇게 “장고”와 “파이썬” 문자열 앞에 공백이 없이 깔끔하게 정리된 꼴이다. 이건 split 메소드와 마찬가지로 파이썬 문자열 built-in 메소드인 strip 으로 할 수 있다.
' django '.strip()
이렇게 하면 'django' 이렇게 앞뒤 공백을 정리한다. 그렇다면 쉼표 단위로 문자열을 쪼갠 다음에 list 자료형을 반복문으로 돌며 strip 메소드로 공백을 제거해야 한다.
tags = [] split_tags = unicode(request.POST['tags']).split(',') for tag in split_tags: tag_list.append(tag.strip())
쪼갠 최종 꼬리표를 tags 에 넣을 것이므로
- tags 를 list 자료형으로 초기화하고(빈값을 넣고)
- 쉼표로 이용자가 입력한 꼬리표 문자열을 쪼개어 split_tags 라는 변수에 넣은 후 (단, 혹시나 숫자가 들어올 수 있으므로 무조건 unicode 문자형으로 강제 변환하였다)
- 이 split_tags 라는 list 자료형 변수를 반복문으로 돌며 값을 하나 하나 꺼내어 tag 에 넣은 뒤
- strip() 메소드로 앞뒤 공백을 없앤 문자열을
- tags 에 추가(append)
하는 것이다. 꽤 단순한 일을 하는 소스인데 4줄이다. 파이썬은 이런 걸 깔끔하게 정리할 수 있는 편리한 문법을 제공하는데, 바로 람다식(lambda expression)이다. 보다 자세한 내용은 이 글 맨 아래에 있는 “파이썬 기초” 부분에서 다루기로 하고, 여기서는 위에 있는 4줄을 람다식과 map 함수를 이용해서 다음과 같이 한 줄로 바꾸기로 하자.
tags = map(lambda str: str.strip(), unicode(request.POST['tags']).split(','))
지금이야 저 소스가 익숙하지 않으니 가독성이 떨어지겠지만, 익숙해지면 정말 소스와 기능이 한 눈에 들어오게 된다.
이제 tags 에는 잘 쪼개놓은 글 꼬리표가 list 자료형으로 예쁘장하게 들어가있다. 이 꼬리표를 글 꼬리표 모델(TagModel)을 이용해 실제 DB에 넣어보자. 우선 DB에 넣을 글 꼬리표가 기존 DB에 이미 있는지 확인해야 한다. 왜냐하면 기존 hannal 이라는 글 꼬리표의 id 가 1이고 이 꼬리표에 글 10, 23번이 연결되어 있는데, 새로운 hannal 꼬리표가 id 10으로 생겼을 경우, hannal 이라는 꼬리표 이름은 같은데 어떤 글은 1번 hannal 꼬리표와 연결되어 있고 어떤 글은 10번 hannal 꼬리표에 연결되는 불상사가 생긴다. 물론 기존 DB에 없는 꼬리표라면 DB에 추가해 넣으면 된다. 자, 그렇다면
for tag in tags: try: TagModel.objects.get(Title=tag) except: # TagModel 에 글 꼬리표 입력 추가
이렇게 하나 하나 찾은 뒤 없으면 추가하는 코드를 짜야 할까? 그래도 되지만 django 에서는 get_or_create 라는 친절한 메소드를 제공해서 좀 더 깔끔하고 알아보기 쉽게 처리할 수 있다.
for tag in tags: (obj, created) = TagModel.objects.get_or_create(Title=tag)
처리할 글 꼬리표의 이름을 가진 글 꼬리표를 DB에서 가져오되(get), 없는 경우 새로 만들어 넣는다(create). 참 깔끔하다.
get_or_create 메소드는 값 두 가지를 tuple 자료형으로 반환한다. 첫 번째 값은(obj) DB에서 가져온 객체(없어서 새로 넣는 경우엔 새로 넣은 뒤 그것을 가져온다)이고, 두 번째는(created) 생성일시이다. 우리가 글을 가져올 때
entry = Entries.objects.get(id=1)
이렇게 가져와서 그 자료(객체)를 entry 에 넣듯이, 반환하는 값 중 첫 번째는 DB에서 가져온 값(객체)을 뜻한다. 두 번째 생성일시는 기존 DB에 없어서 새로 만들어 넣는 경우에 발생하는 값으로, 이미 DB에 있어서 새로 만들어 넣는 게 아닌 경우엔 이 값은 False 가 된다.
글 꼬리표는 1개 이상이다. 그러므로 get_or_created 가 반환하는 값 중 첫 번째 값인 obj 도 list 자료형에 차곡 차곡 담아야 한다. created 는 굳이 쓰진 않으니 obj 만 받아다 담자.
tag_list = [] for tag in tags: tag_list.append(TagModel.objects.get_or_create(Title=tag)[0])
append 는 위에서 이미 익혔다. 좀 다른 점은 TagModel.objects.get_or_create(Title=tag) 이 뒤에 [0] 를 붙인 것인데, get_or_created 가 반환값 두 개를 tuple 자료형으로 반환하는 것이므로 첫 번째 값인 obj만 받아내기 위해 [0] 라고 한 것이다. 만약 created 만 받고 싶다면 [1] 이라고 하면 된다.
이 세 줄짜리 소스 코드를 아까처럼 한 줄로 줄일 수 있을까? 가능하다. 위에서 람다식과 map 함수를 쓴 것처럼
tag_list = map(lambda tag: TagModel.objects.get_or_create(Title=tag)[0], tags)
라고 하면 된다. 위에서 다루지 않은 문법으로도 처리할 수 있다.
tag_list = [TagModel.objects.get_or_create(Title=tag)[0] for tag in tags]
for 반복문을 안에다 넣은 것이다. 우리에겐 참 암호같은 소스 코드이지만, 저 문법은 영어 문장 구조(문법)과 비슷하다. that 절 느낌이랄까? ^^
- I believe that you can do it.
- A) 나는 안다 / B) 너가 해낼 수 있으리란 걸.
- B) 부분을 that 앞으로 떠넘기어서
- => 나는 너가 해낼 수 있으리란 걸 안다.
중학생 때 성문영어 문법책을 볼 때 저걸 공부하며 that 절을 무척 미워했던 기억이 난다. (성문영어 참고서가 아니었나?)
어쨌든 굳이 저런 식으로 소스 코드를 쓴 이유는 파이썬을 공부하며 인터넷에서 남이 짠 소스를 보다보면 다분히 영어 문장 구조를 따르는 저런 표현식을 쓰는 소스 코드를 심심치 않게 만나기 때문이다. 우리는 자주 쓰지 않더라도 소스 코드를 알아볼 눈은 갖춰야 하니까 말이다. 사람 마다 취향이 다르겠지만, 난 람다와 map 함수를 권하고 싶다.
이제 글 꼬리표 처리도 다 끝났다. 정리하면 이렇게 표현할 수 있다.
if request.POST.has_key('tags') == True: tags = map(lambda str: str.strip(), unicode(request.POST['tags']).split(',')) tag_list = map(lambda tag: TagModel.objects.get_or_create(Title=tag)[0], tags) else: tag_list = []
고작 이 다섯 줄을 설명하려고 이렇게 넓게 둘러봤다. ^^
1차 저장
응? 1차 저장? 저장이면 저장이지 1차 저장은 무엇이람.
실은 이것도 다 “글 꼬리표” 때문이다. 글 꼬리표 모델(TagModel)과 글 정보 모델(Entries)은 MANY TO MANY 관계이다. 이런 관계에서 글을 저장할 때 글 꼬리표를 매달려면 먼저 글 꼬리표를 매달지 않은 상태에서 글을 저장하여 글의 일련번호(id), 정확히 말하자면 DB 테이블의 기본 키(Primary Key)를 먼저 만든 뒤에 글 꼬리표를 매달아야 한다.
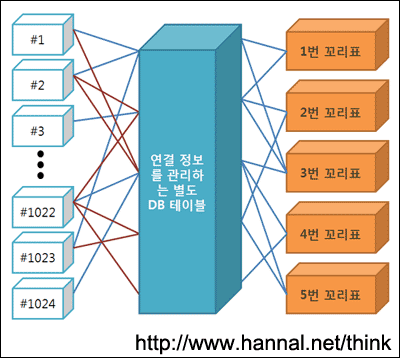
이 그림을 기억했으면 좋겠다. “미) 파이썬 기초 문법과 데이터 모델링 (4편 2/2)” 에서 MANY TO MANY 관계형을 설명할 때 본 그림이다. 이렇게 MANY TO MANY 관계형에선 두 모델 사이에서 두 모델에 속한 자료를 서로 잇는 DB 테이블이 있다고 배웠다. 글과 글 꼬리표로 치면, 이 테이블엔 글 일련번호(id)와 글 꼬리표 일련번호(id)가 서로 이어져 있는 것이다. 바로 그렇기 때문에 글 일련번호가 필요한 것이다. 글 일련번호가 있어야 글 꼬리표를 이을 수 있도록 이 테이블에 관계를 정의할 수 있기 때문이다.
django 모델을 이용해 자료를 DB에 저장하는 방법은 어렵지 않다. 우리는 글 정보를 넣을 것이므로
new_entry = Entries(Title=entry_title, Content=entry_content, Category=entry_category)
이렇게 하면 된다. 차근 차근 살펴보자. 위 한 줄 소스 코드는 이렇게 풀어 쓸 수 있다.
new_entry = Entries()
new_entry.Title = entry_title
new_entry.Content = entry_content
new_entry.Category = entry_category
글 정보 모델(Entries)은 파이썬 코드로 봤을 때 클래스 객체이다. Entries 라는 클래스 객체를 new_entry 라는 변수(객체)에 할당하기 위해 new_entry = Entries() 라고 했다. 그런 뒤 이 클래스의 프로퍼티들인 Title, Content, Category (Entries 모델 만들 때 만들어 놓은 그 녀석들 맞다)에 넣을 값을 넣는다. 이걸 한 줄로 줄여쓴 것이
new_entry = Entries(Title=entry_title, Content=entry_content, Category=entry_category)
이것이다. 이렇게 하면 Entries 클래스(모델)를 할당 받은 new_entry 에 프로퍼티로 우리가 이용자로부터 넘겨받은 글 제목, 본문, 글 갈래를 넣는다. (방금 설명한 내용은 객체 지향 프로그래밍을 제공하는 프로그래밍 언어를 할 때 클래스를 할당하는 기본 문법과 관련된 내용이다. “변수 = new 뭐시기()” 이렇게 생긴 코드들이 바로 그것이다.)
이제 이 클래스에 있는 save 메소드를 이용해 DB에 실제로 넣으면 된다.
new_entry.save()
save 메소드가 Entries 클래스에 있던 이유는 이 클래스가 django 의 db 클래스를 상속 받았기 때문인데, 이 django db 클래스가 물려주는 유산 중에는 실제 DB에 값을 넣거나(INSERT) 값을 바꾸는(UPDATE) save 메소드가 있다. 물려 받았으니 쓸 수 있는 것이다.
2차 저장
이번엔 글 꼬리표도 매달 차례이다. 글 꼬리표는 1개 이상일 수 있기에 list 자료형인 tag_list 에 차곡 차곡 글 꼬리표들을 담아놨다. for 반복문으로 하나씩 꺼내서 글에 매달면 된다.
for tag in tag_list: new_entry.Tags.add(tag)
new_entry는 Entries 클래스라는 모델을 할당 받은 것이다. Entries 모델엔 Tags 라는 요소가(프로퍼티) ManyToMany 로 정의되어 있다.
class Entries(models.Model): Title = models.CharField(max_length=80, null=False) Content = models.TextField(null=False) created = models.DateTimeField(auto_now_add=True, auto_now=True) Category = models.ForeignKey(Categories) Tags = models.ManyToManyField(TagModel) Comments = models.PositiveSmallIntegerField(default=0, null=True)
models.py 에 있는 위 모델 내용 중 Tags 부분을 보면 그렇다. 이 Tags 에는 여러 메소드가 있다. 지난 글에서 글에 달린 모든 글 꼬리표를 가져오려고 list.html 나 read.html 에서 {% for tag in entry.Tags.all %} 이런 템플릿 구문을 썼었다. 바로 entry.Tags.all 에서 all 메소드가 있듯이 저 new_entry.Tags 에도 add 메소드가 있다. 물론 all 메소드도 있다. entry 라는 놈이든 new_entry 라는 놈이든 같은 놈이나 마찬가지이기 때문이다.
new_entry 라는 글 객체는 방금 새로 DB에 저장한 새 글 객체이다. 이 객체에 있는 Tags 에는 add 메소드가 있는데 이 메소드는 Tags 에 연결된 다른 모델에 값을 추가(add)하여 연결하는 것이다. 우리는 글 꼬리표를 추가해 연결할 것이므로 for 반복문으로 tag_list 에서 글 꼬리표를 하나씩(tag) 꺼내어 add 로 추가한 것이다.
글 꼬리표들까지 모두 매달았다. 물론 글 꼬리표 자체를 이용자가 써넣지 않았다면 tag_list 는 빈 list 자료형이므로 글 꼬리표는 넣지 않을 것이고, 그러면 굳이 2차 저장을 할 필요는 없다. 즉 글 꼬리표가 있는 경우에만 2차 저장을 하여 글 꼬리표를 매달면 되므로
if len(tag_list) > 0: new_entry.save()
라고 하면 된다.
그런데 글 저장하다가 오류가 생기는 일은 없을까? 예를 들면, DBMS에 문제가 생겼다거나 우리 예상을 벗어나는 매우 신기한 값을 이용자가 입력해서 DB에 값을 넣지 못하는 경우 말이다. 물론 생길 수 있다. 그런 문제가 생기면 파이썬 예외 상황(Exception) 오류가 발생한다. 모델을 통해 DB에서 자료를 가져올 때 가져올 조건을 만족하는 자료가 없으면 예외 상황 오류가 발생한 것처럼 말이다. 이런 경우를 대비하려면 마찬가지로 예외 상황 처리 구문을 써야 한다. 1차 저장에 먼저 적용하자.
try: new_entry.save() except: return HttpResponse('글을 써넣다가 오류가 발생했습니다.')
오류가 발생하면 작업을 중단하고 위와 같은 오류 안내말을 출력한다.
이번엔 2차 저장에 적용한다.
if len(tag_list) > 0: try: new_entry.save() except: return HttpResponse('글을 써넣다가 오류가 발생했습니다.')
그리고 함수 맨 마지막에 있던
return HttpResponse('hello %s' % entry_category.Title)
내용도 저장 성공 안내말로 바꾼다.
return HttpResponse('%s번 글을 제대로 써넣었습니다.' % new_entry.id)
강좌 내용을 잘 따라왔다면 글이 잘 들어갈 것이다.

이렇게 해서 글 저장까지 끝냈다. “10분만에 블로그 만들기 동영상 설명”을 보면 이 정도 기능까지 만들고 블로그를 다 만들었다고 뻥친다. 아주 뻥이라고만 할 수는 없는 것이 스카폴딩 기능(django 라면 admin 기능)을 이용하면 단 몇 분 만에 댓글 달기 기능도 구현할 수 있기 때문에 설명에서 생략했기 때문이다. 그렇게 치면 우리도 7회 만에 블로그 하나 만들었다. ^^
다음 글에서는 댓글 입력과 출력 기능을 만들 것이다. 다음 주까지 마치면 블로그 기능 중 가장 기본이라 할 수 있는 글 쓰기, 글 목록 보기, 글 낱장 보기, 댓글 달기, 댓글 보기까지 다 만들게 된다. 이것 말고도 RSS 기능이나 글 수정 기능도 만들겠지만, 어떤 건 숙제로 나가고 어떤 건 좀 더 나중에 만들 것이다.
예전에 다른 프로그래밍 언어나마 익혀서 다뤄본 적 있는 이라면 이 정도만 되어도 아직 우리가 만들지 않은 기능들을 스스로 만들려고 덤벼들 것이라 생각한다. 자료를 DB에 써넣고 끄집어내는 주요 기능이나 문법 같은 건 이번 글을 통해 상당 수 다뤘기 때문이다. 실제로 강좌도 전회 중 거의 절반쯤 마쳤다(분량으로 치면 거의 2/3). 이전 글과 이번 글은 양이 많아 공부할 때 힘들었겠지만 조금만 더 나아가면 우리나라에서 django 로 블로그 만들 줄 아는 몇 안되는 사람 중 한 명이 되니 좀 더 힘을 내자. :)
파이썬 기초
UTF-8 와 len 함수
혹시 프로그래밍 공부를 조금 해본 이라면 영문은 한 글자가 1바이트(byte) 이고 한글이나 한자 같은 건 2바이트라는 걸 알 것이다. 그러므로 len('hannal') 은 6이 반환되고 len('한날') 은 4가(1글자는 2바이트이므로) 반환된다고 생각할 수 있다.
UTF-8 에선 다르다. UTF-8 에선 영문이든 한글이든 모두 바이트 단위가 아닌 글자 단위로 처리한다. 그래서 len(u'한날') 이라고 하면 4가 아닌 2가 출력된다. 2 바이트가 아니라 2글자가 되는 것이다. (앞에 u 는 유니코드라는 표시이다)
그렇다면 UTF-8 문자열을 아스키 문자열로 변환하면 값이 달라질까? 우리는 encode 메소드를 이용해 유니코드 문자열을 아스키로 변환했으니, 이걸 이용해서 확인해보자.
len(u'한날'.encode('utf-8'))
유니코드인 한날 문자열(u'한날')을 encode 메소드로 변환한 것인데, 숫자는 4가 아니라 6이 뜬다. UTF-8 에서 한글은 2바이트가 아니라 3바이트이기 때문이다.
has_key 메소드
딕셔너리 자료형에서 특정 키가 있는지 확인하는 방법으로 has_key 메소드를 배웠다. 실은 이보다 더 간편한 방법이 있다. 바로 in 이다. 아래 두 코드는 동일하게 작동한다.
1. has_key 메소드 쓰기
if dict_var.has_key('hannal'): print 'the key is existed'
2. if 조건문의 in 쓰기
if 'hannal' in dict_var: print 'the key is existed'
모양새가 for 문과 비슷하다고 생각했는가? 대단한 눈썰미이다. :)
람다식와 map 함수
우리는 위에서
tags = [] split_tags = unicode(request.POST['tags']).split(',') for tag in split_tags: tag_list.append(tag.strip())
이 4줄을
tags = map(lambda str: str.strip(), unicode(request.POST['tags']).split(','))
이렇게 한 줄로 줄였다. 여기서 눈에 띄이는 애들이 있는데 바로 map 함수와 lambda(람다)식이다. 람다부터 보자.
람다식은 함수와 거의 똑같다. 함수처럼 인자를 받고, 이를 처리해서 값을 반환한다. 차이점이라면 람다는 “딱 한 줄”로만 표현할 수 있다.
def a_plus_b(a, b): return a + b
위 함수는 인자로 a와 b를 받은 뒤 이 둘을 더해서 그 값을 반환한다. 이를 람다식으로 표현하면
lambda a, b: a + b
로 된다. 반환문인 return 도 없다. manage.py shell 이라고 해서 파이썬 명령 프롬프트 상태로 가서 직접 확인해보자.
>>> lmd = lambda a, b: a + b
>>> lmd(10, 23)
33

lambda a, b: a + b 라는 람다식을 lmd 에다 넣고 lmd를 실행할 때 인자로 10과 23을 넣자 이 둘을 더한 값이 반환된다.
아주 간단한 식을 함수처럼 값을 받아다 처리하고 싶은데 함수로 만들자니 거창하고, 그렇다고 재사용 할 일도 없으면 람다식으로 깔끔하고 편하게 처리할 수 있다.
이런 람다식과 함께 쓰면 참 편리하고 강력한 함수가 몇 개 있는데 filter 함수나 map, reduce 같은 함수가 있다. 이들에 대한 설명은 http://turing.cafe24.com/ 에서 연재 중인 파이썬 강좌 중 람다 부분을 참고하길 바란다.